





Saturday, December 15, 2018
Thursday, December 13, 2018
(Solved) Free storage dropped to 0 on aurora/rds node
When the slow_log is enabled and the long_query_time is set to 0 , this will cause the instance to log all the queries on the DB.
This can cause the downtime in the Database always ensure you are not enabling these settings to log everything , it should only be enabled for a short period of time for debugging purpose only.
This can cause the downtime in the Database always ensure you are not enabling these settings to log everything , it should only be enabled for a short period of time for debugging purpose only.
Wednesday, December 12, 2018
TLS 1.3 support with nginx plus
TLS 1.3 support is now available, bringing the latest performance and security improvements to transport layer security. This includes 0-RTT support, for faster TLS session resumption. TLS 1.3 can be used to provide secure transport for both HTTPS and TCP applications. OpenSSL 1.1.1 or newer is required to provide TLS 1.3. At the time of release OpenSSL 1.1.1 is available with Ubuntu 18.10 and FreeBSD 12 (shortly after release).
Tuesday, December 11, 2018
Storing AWS passwords secretly on mac
If you are managing large number of the AWS Accounts in your organisation than its better to use some federated solution.
However if you are using passwords only than you can use the KeepPassXC
https://keepassxc.org/download/#mac
To securely store all your passwords in the keepassxc.
It maintains its own database and you can take the backup of the database to keep your password safe. It does not sync them externally thus lowering the threat of compromise.
In case your laptop corrupts you can import the database which was created earlier and you would be able to see the credentials.
Everytime you open your database you will have to unlock it initially before gaining access to the secrets.
Its much of the use is similar to the Hashicorp vault just the difference is instead of application making the request you keep your password in the keepassXC.
However if you are using passwords only than you can use the KeepPassXC
https://keepassxc.org/download/#mac
To securely store all your passwords in the keepassxc.
It maintains its own database and you can take the backup of the database to keep your password safe. It does not sync them externally thus lowering the threat of compromise.
In case your laptop corrupts you can import the database which was created earlier and you would be able to see the credentials.
Everytime you open your database you will have to unlock it initially before gaining access to the secrets.
Its much of the use is similar to the Hashicorp vault just the difference is instead of application making the request you keep your password in the keepassXC.
Important points regarding the use of the spot instances in the AWS
1. If you are using the balanced orientation which is a mix of cost orientation along with the availability orientation, it means it will always launch instances that have lowest pricing at the moment in the Az's along with the longest duration without any disruptions. Spot instances service provider usually make choices based on the lowest pricing and long lasting instances. But this does not mean these service provider will evenly spread between AZ's i.e. balanced orientation is not always balanced distribution.
2. You can usually change this by selecting the availability orientation but this options narrows down the possibility of long continuity instance types in case volatility increases so choose that option with consideration.
3. Now there can be issue in case your subnet is not having sufficient capacity to create more ip address. This can happen when there are not enough free addresses available in the subnet to satisfy the requested number of instance.
4. Also if the instances has already reached the maximum number of instances in elasticgroup configuration than also new instances won't be spawn so in this case you should monitor the value i.e. current instances is always 25% lower than maximum instances in case you receive some spike and more containers are required to be deployed due to which more servers are required to spin up.
2. You can usually change this by selecting the availability orientation but this options narrows down the possibility of long continuity instance types in case volatility increases so choose that option with consideration.
3. Now there can be issue in case your subnet is not having sufficient capacity to create more ip address. This can happen when there are not enough free addresses available in the subnet to satisfy the requested number of instance.
4. Also if the instances has already reached the maximum number of instances in elasticgroup configuration than also new instances won't be spawn so in this case you should monitor the value i.e. current instances is always 25% lower than maximum instances in case you receive some spike and more containers are required to be deployed due to which more servers are required to spin up.
Wednesday, December 5, 2018
Aliyun Cloud Important Points
There are two versions available for aliyun cli
- CLI Go Version
- CLI Python Version
Make sure Go Version is to be installed as python version is going to be deprecated.
You can refer to the below link for the Aliyun Cli installation
https://github.com/aliyun/aliyun-cli?spm=a2c63.p38356.a3.1.17414388la2EgQ
Creating a VPN Tunnel
- Create VPN Gateway.
- Create Customer Gateway and enter Office Gateway IP as Customer gateway IP address.
- Create IPSec Connection. Consider following important points -
Local Network - VPC CIDR
Remote Network - Office Network CIDR
Encryption Algorithm - aes192 - Download vpn configuration and share with network team. In mail, mention ports to be opened usually 22, 80, 443.
- Once the network team has configured the configuration on there end of tunnel. Tunnel will be up in IPSec connection section.
- Update route table. Allow required port from the other end of the Tunnel NAT IP to allow the traffic to flow securely over the private tunnel.
Sunday, December 2, 2018
Most Important Security Practices
- Remove all passwords, keys etc from code and use vaults/jks etc for storing them securely
- Review all exposed APIs in terms of sanitising input params, build rate controls, authentication, and source whitelisting
- Build DDoS protection by reviewing perimeter architecture, implementing a WAF, put request rate limits at load balancer
- Keep reviewing all security groups, firewall rules, patch any system with vulnerable components
- Start secure code reviews for all releases and review input sanitisation, query parameterisation and other OWASP items.
Best Practices with Mysql Databases
- Stored Procedures should not be used.
- All Queries taking more than 500 ms are classified as Bad Queries and will be considered as Blocker Bugs
- No unnecessary complex joins and no shared databases across multiple applications/services.
- Every database should have it's own Access Control
- Connections and Throttle Limits should be setup.
- Schema Migrations should not have any down time.
- Every database should have a Candidate Master and Multi-Redundancy
- Every database should have Orchestration setup with auto failure mode setup.
- All databases should be part of Monitoring
Database Proxy
Database proxy is a middleware which once setup in place will ensure that all reads/writes from the application passes through it. It can serve following purposes.
1) Balancing the load due to queries being performed on database. In most setups, database slaves are used with a DNS. This doesn't help in balancing the queries which are being performed on the slaves. It has been observed that while one slave is heavily loaded, the other is almost idle which clearly indicates balancing is not done in the right way and overall performance of the read queries are also degrading than the resources being used.
2) Routing/Rejecting queries based on regex. This allows the Engineering team to have the capability of blacklist filters on certain clauses depending upon the current indexes in the table. This will ensure, queries executed from mysql cli client do not impact critical slaves. There is more that can be achieved with this feature.
3) Automatically shun slaves with replication lag ProxySQL automatically stops routing the queries to a slave that are facing lag. No more replication lag related bugs.
ProxySQL
To achieve above requirements/goals, the ProxySQL should be used. ProxySQL is a high performance MySQL proxy that can scale up to hundreds of backend servers.
Topology

Integration
Application that want to leverage the proxy can use the Proxy ELB DNS in their applications rather than using the DNS. Database teams can setup the required Slave server host group.
Engineering Best practices to be followed
1. All teams should use confluence:-
i.e. all team documents, on call process, how to, team details etc should be publish to the confluence itself. Documents should not be shared in the email of texts.
2. Publish Design documents for future release:-
Design documents should have following structure
Status, authors, reviewers, overview, goals both business level and tech level goals, Design, Architecture, Tech stack, changes in existing systems, APIS, public apis, non public apis, security, system infra details, testing , monitoring and alerting, disaster recover, failover, production readiness checklist, faqs.
3. Code quality:-
a. Supported ides and minimum version.
b. Use of bitbucket/gitlab and code style guildlines
4. Code Documentations and Guidelines:-
a. Code commit should have JIRA ID with each and every commit
b. Release branches should be properly defined.
5. Code Review:-
a. publish code review checklist
b. Tools to track code review
c. Cross teams review for critical features.
i.e. all team documents, on call process, how to, team details etc should be publish to the confluence itself. Documents should not be shared in the email of texts.
2. Publish Design documents for future release:-
Design documents should have following structure
Status, authors, reviewers, overview, goals both business level and tech level goals, Design, Architecture, Tech stack, changes in existing systems, APIS, public apis, non public apis, security, system infra details, testing , monitoring and alerting, disaster recover, failover, production readiness checklist, faqs.
3. Code quality:-
a. Supported ides and minimum version.
b. Use of bitbucket/gitlab and code style guildlines
4. Code Documentations and Guidelines:-
a. Code commit should have JIRA ID with each and every commit
b. Release branches should be properly defined.
5. Code Review:-
a. publish code review checklist
b. Tools to track code review
c. Cross teams review for critical features.
Friday, November 23, 2018
[Solved] Error: (!log_opts) Could not complete SSL handshake with : 5
If you are working with the nrpe and just compiled with the nrpe but not able to start the nrpe service on the 5666 port its because you have not compiled it with the SSL support.
So to resolve this issue you need to recompile it with the SSL support to overcome this issue as
cd nrpe-3.2.1
./configure --enable-ssl
If you already have use the --enable-ssl than you might not have added the ip address in the /etc/nagios/nrpe.cfg
only_from = 127.0.0.1 192.168.33.5
So to resolve this issue you need to recompile it with the SSL support to overcome this issue as
cd nrpe-3.2.1
./configure --enable-ssl
If you already have use the --enable-ssl than you might not have added the ip address in the /etc/nagios/nrpe.cfg
allowed_hosts=127.0.0.1,192.168.33.5In case you are using xinetd or inetd services than you need to change /etc/xinetd.d/nrpe
only_from = 127.0.0.1 192.168.33.5
Thursday, November 22, 2018
Dividing CIDR into AWS with Range and server with UI
In case you are creating a new VPC and have selected the CIDR Range and want to divide the CIDR with proper ranges along with the number of usable ips , counts, ranges . You can use the following online tool where you can do it everything in UI thus reducing the overall error and managing overall information much more conveniently.
http://www.davidc.net/sites/default/subnets/subnets.html
Just update the CIDR Block Range like 10.0.0.0/16 and than you can start dividing the subnet as per your use case and incorporate the same in your VPC.
http://www.davidc.net/sites/default/subnets/subnets.html
Just update the CIDR Block Range like 10.0.0.0/16 and than you can start dividing the subnet as per your use case and incorporate the same in your VPC.
 |
| AWS Subnet Calculator from CIDR Tool |
Monday, November 12, 2018
[Solved] jenkins java.lang.IllegalArgumentException: Not valid encoding '%te'
After a fresh jenkins installation, I was getting this error when i created the user.
Caused by: java.lang.IllegalArgumentException: Not valid encoding '%te'
at org.eclipse.jetty.util.UrlEncoded.decodeHexByte(UrlEncoded.java:889)
at org.eclipse.jetty.util.UrlEncoded.decodeUtf8To(UrlEncoded.java:522)
at org.eclipse.jetty.util.UrlEncoded.decodeTo(UrlEncoded.java:577)
at org.eclipse.jetty.server.Request.extractFormParameters(Request.java:547)
at org.eclipse.jetty.server.Request.extractContentParameters(Request.java:471)
at org.eclipse.jetty.server.Request.getParameters(Request.java:386)
... 91 more
Caused by: java.lang.IllegalArgumentException: Not valid encoding '%te'
at org.eclipse.jetty.util.UrlEncoded.decodeHexByte(UrlEncoded.java:889)
at org.eclipse.jetty.util.UrlEncoded.decodeUtf8To(UrlEncoded.java:522)
at org.eclipse.jetty.util.UrlEncoded.decodeTo(UrlEncoded.java:577)
at org.eclipse.jetty.server.Request.extractFormParameters(Request.java:547)
at org.eclipse.jetty.server.Request.extractContentParameters(Request.java:471)
at org.eclipse.jetty.server.Request.getParameters(Request.java:386)
... 91 more
Solution:- Just restart the jenkins service that should fix the issue.
Wednesday, October 31, 2018
[Solved] Stderr: VBoxManage: error: The virtual machine 'master_default_1540967069723_95784' has terminated unexpectedly during startup with exit code 1 (0x1)
Error:-
There was an error while executing `VBoxManage`, a CLI used by Vagrant
for controlling VirtualBox. The command and stderr is shown below.
Command: ["startvm", "cddac55c-debe-470d-bb0a-d5badf0c19af", "--type", "gui"]
Stderr: VBoxManage: error: The virtual machine 'master_default_1540967069723_95784' has terminated unexpectedly during startup with exit code 1 (0x1)
VBoxManage: error: Details: code NS_ERROR_FAILURE (0x80004005), component MachineWrap, interface IMachine
Solution:-
1. So here is a brief of what I was doing, i installed the virtualbox on my macos using the brew and installed the vagrant than and tried to bring up the vm using vagrant which resulted in above error.
2. The problem is because the MACOS doesn't allow the changes in the kernel modules by some external application due to which the installation of the Virtualbox fails on MacOS
3. To resolve this issue download the virtualbox installer from the virtualbox site and instead of using brew to install the virtualbox use the installer.
http://download.virtualbox.org/virtualbox/5.2.20
4. Now once it fails open the Security & Privacy setting and click on allow option as below

5. Once you have clicked on allow option , try reinstalling again and you should be able to install it successfully this time.
6. Now the vagrant up and it will also work.
There was an error while executing `VBoxManage`, a CLI used by Vagrant
for controlling VirtualBox. The command and stderr is shown below.
Command: ["startvm", "cddac55c-debe-470d-bb0a-d5badf0c19af", "--type", "gui"]
Stderr: VBoxManage: error: The virtual machine 'master_default_1540967069723_95784' has terminated unexpectedly during startup with exit code 1 (0x1)
VBoxManage: error: Details: code NS_ERROR_FAILURE (0x80004005), component MachineWrap, interface IMachine
Solution:-
1. So here is a brief of what I was doing, i installed the virtualbox on my macos using the brew and installed the vagrant than and tried to bring up the vm using vagrant which resulted in above error.
2. The problem is because the MACOS doesn't allow the changes in the kernel modules by some external application due to which the installation of the Virtualbox fails on MacOS
3. To resolve this issue download the virtualbox installer from the virtualbox site and instead of using brew to install the virtualbox use the installer.
http://download.virtualbox.org/virtualbox/5.2.20
4. Now once it fails open the Security & Privacy setting and click on allow option as below

5. Once you have clicked on allow option , try reinstalling again and you should be able to install it successfully this time.
6. Now the vagrant up and it will also work.
Installing the virtualbox on mac using brew
Use the following command to install the virtualbox on the mac using brew
brew cask install virtualbox Thursday, October 25, 2018
Managing Multiple VPC in Organization
If you are managing a very large infrastructure which is spawned across multiple Public clouds, private datacenters and have large number of external integration with the multiple merchants over the tunnel , its good to maintain the Network details for all the Public clouds (AWS-VPC), private datacenters etc so that there is no overlapping between your account and some other team account with whom you might have to peer or create a tunnel in a later point in time. Its good to maintain a wiki page for the same and everytime there is a requirement for the New infrastructure creation always update the wiki for the same.
For the AWS you can prepare a excel sheet with the following fields to relay the information correctly to other teams:-
1. Network details
2. CIDR
3. Broadcast IP
4. Netmask
5. Location
6. Comments
For private datacenters enter the following details
1. Subnet
2. Mask
3. Subnet Details
4. VLAN ID
5. Zone/VLAN
6. Gateway
For the AWS you can prepare a excel sheet with the following fields to relay the information correctly to other teams:-
1. Network details
2. CIDR
3. Broadcast IP
4. Netmask
5. Location
6. Comments
For private datacenters enter the following details
1. Subnet
2. Mask
3. Subnet Details
4. VLAN ID
5. Zone/VLAN
6. Gateway
Enable or Disable passphrase on id_rsa key file
It's always good to have a passphrase entered whenever you are generating any ssh-key for the server access as it helps to prevent unauthorised access in case you key is compromised from the security point of view and are mostly the requirement of the audits as it act as an two factor authentication which requires the passphrase and secure key entered to access the server.
You can also enable the google authentication in which case it will generate a passcode on applications such as google authenticator and apart from the passphrase and key a person accessing the server would need to enter the google authenticator code as well in order to access the server thus increasing the security even further. Covered this in my previous post below
In case you forget to enable the passphrase and want to enable it now use the following command to enable the passphrase without effecting your existing key file
ssh-keygen -p -f ~/.ssh/id_rsa
Simply and enter your passphrase 2 times and now every time you ssh to server with your key you will need to enter this passphrase.
In case you want to remove the passphrase use the following command
ssh-keygen -p
enter your old passphrase and leave it blank afterwards. This basically overrides your previous passphrase with blank passphrase.
You can also enable the google authentication in which case it will generate a passcode on applications such as google authenticator and apart from the passphrase and key a person accessing the server would need to enter the google authenticator code as well in order to access the server thus increasing the security even further. Covered this in my previous post below
In case you forget to enable the passphrase and want to enable it now use the following command to enable the passphrase without effecting your existing key file
ssh-keygen -p -f ~/.ssh/id_rsa
Simply and enter your passphrase 2 times and now every time you ssh to server with your key you will need to enter this passphrase.
In case you want to remove the passphrase use the following command
ssh-keygen -p
enter your old passphrase and leave it blank afterwards. This basically overrides your previous passphrase with blank passphrase.
Wednesday, October 3, 2018
Elasticsearch monitoring
What is Elastic Search?
- Elasticsearch is an open source distributed document store and search engine that stores and retrieves data structures in near real-time.
- Elasticsearch represents data in the form of structured JSON documents, and makes full-text search accessible via RESTful API and web clients for languages like PHP, Python, and Ruby.
Few Key Areas to monitor Elastic Search in DataDog:
- Search and indexing performance
- Memory and garbage collection
- Host-level system and network metrics
- Cluster health and node availability
- Resource saturation and errors
Search and indexing performance:
Search Performance Metrics:
- Query load : Monitoring the number of queries currently in progress can give you a rough idea of how many requests your cluster is dealing with at any particular moment in time.
- Query latency: Though Elasticsearch does not explicitly provide this metric, monitoring tools can help you use the available metrics to calculate the average query latency by sampling the total number of queries and the total elapsed time at regular intervals
- Fetch latency: The second part of the search process, the fetch phase, should typically take much less time than the query phase. If you notice this metric consistently increasing, this could indicate a problem with slow disks, enriching of documents (highlighting relevant text in search results, etc.), or requesting too many results.



Indexing Performance Metrics:
- Indexing latency:
If you notice the latency increasing, you may be trying to index too many documents at one time (Elasticsearch’s documentation recommends starting with a bulk indexing size of 5 to 15 megabytes and increasing slowly from there).
solution:
If you are planning to index a lot of documents and you don’t need the new information to be immediately available for search, you can optimize for indexing performance over search performance by decreasing refresh frequency until you are done indexing
2. Flush latency:
If you see this metric increasing steadily, it could indicate a problem with slow disks; this problem may escalate and eventually prevent you from being able to add new information to your index
Important points for Elasticsearch Optimizations
Points to be taken care before creating cluster:
Config walk-through:
cluster.name:
Represents the name of the cluster and it should be same across the nodes in the cluster.
node.name:
Represent the name of the particular node in the cluster. It must be unique for every node and it is good to represent the hostname.
path.data:
Location where the elasticsearch need to store the index data in disk. If you are planning to handle huge amount of data in the cluster, it is good to point to another EBS volume instead of root volume.
path.logs:
Location where the elasticsearch needs to store the server startup, indexing and other logs. It is also good to store at other than EBS volume.
bootstrap.memory_lock:
This is an important config in ES config file. This needs to set as "TRUE". This config locks the amount of heap memory that is configured in the JAVA_ARGS to elasticsearch. If it is not configured, the OS may swap out the data of ES into disk and in-turn garbage collections may take more than a minute instead of milliseconds. This directly affects the node status and chances are high that the nodes may come out of the cluster.
network.host:
This config will set both network.bind.host and network.publish.host. Since we are trying to configuring the ES as cluster, bind and publish shouldn't be localhost or loopback address.
discovery.zen.ping.unicast.hosts:
This config need to hold all the node resolvable host-name in the ES cluster.
Never .. Ever.. Enable multicast ping discovery. That will create unwanted ping checks for the node discovery across the infrastructure(say 5 nodes, that pings all the 100 servers in the infra. Its bad). Also it is deprecated in Elasticsearch 5.x
discovery.zen.minimum_master_nodes:
Number of master eligible nodes need to be live for deciding the leader. The quorum can be calculated by (N/2)+1. Where N is the count of master eligible nodes. For three master node cluster, the quorum is 2. This option is mandatory to avoid split brains.
index.number_of_shards:
Set the number of shards (splits) of an index (5 by default).
index.number_of_replicas:
Set the number of replicas (additional copies) of an index (1 by default).
Cluster topology:
Cluster topology can be defined mainly with these two config. node.data and node.master.
There is a difference between master and master eligible nodes. Setting node.master will make the node as master eligible node alone. When the cluster is started, the ES itself elects one of the node from the master eligible node to make it master node. We can get the current master node from the ES API "/_cat/nodes?v" . Any cluster related anomolies will be logged at this master node log only.
Cluster optimization for stability and performance:
- Volume of data
- Nodes and capacity planning.
- Balancing, High availability, Shards Allocation.
- Understanding the queries that clusters will serve.
Config walk-through:
cluster.name:
Represents the name of the cluster and it should be same across the nodes in the cluster.
node.name:
Represent the name of the particular node in the cluster. It must be unique for every node and it is good to represent the hostname.
path.data:
Location where the elasticsearch need to store the index data in disk. If you are planning to handle huge amount of data in the cluster, it is good to point to another EBS volume instead of root volume.
path.logs:
Location where the elasticsearch needs to store the server startup, indexing and other logs. It is also good to store at other than EBS volume.
bootstrap.memory_lock:
This is an important config in ES config file. This needs to set as "TRUE". This config locks the amount of heap memory that is configured in the JAVA_ARGS to elasticsearch. If it is not configured, the OS may swap out the data of ES into disk and in-turn garbage collections may take more than a minute instead of milliseconds. This directly affects the node status and chances are high that the nodes may come out of the cluster.
network.host:
This config will set both network.bind.host and network.publish.host. Since we are trying to configuring the ES as cluster, bind and publish shouldn't be localhost or loopback address.
discovery.zen.ping.unicast.hosts:
This config need to hold all the node resolvable host-name in the ES cluster.
Never .. Ever.. Enable multicast ping discovery. That will create unwanted ping checks for the node discovery across the infrastructure(say 5 nodes, that pings all the 100 servers in the infra. Its bad). Also it is deprecated in Elasticsearch 5.x
discovery.zen.minimum_master_nodes:
Number of master eligible nodes need to be live for deciding the leader. The quorum can be calculated by (N/2)+1. Where N is the count of master eligible nodes. For three master node cluster, the quorum is 2. This option is mandatory to avoid split brains.
index.number_of_shards:
Set the number of shards (splits) of an index (5 by default).
index.number_of_replicas:
Set the number of replicas (additional copies) of an index (1 by default).
Cluster topology:
Cluster topology can be defined mainly with these two config. node.data and node.master.
node.data
|
node.master
|
State
|
|---|---|---|
| false | true | only serves as master eligible node and no data will be saved there |
| false | false | Works as loadbalancer for queries and aggregations. |
| true | true | master eligible node and that will save data in the location "path.data" |
| true | false | only serves as data node |
There is a difference between master and master eligible nodes. Setting node.master will make the node as master eligible node alone. When the cluster is started, the ES itself elects one of the node from the master eligible node to make it master node. We can get the current master node from the ES API "/_cat/nodes?v" . Any cluster related anomolies will be logged at this master node log only.
Cluster optimization for stability and performance:
- Enable the memory locking(bootstrap.memory_lock) in elasticsearch.yml
- Set MAX_LOCKED_MEMORY= unlimited and ES_HEAP_SIZE(xmx and xms) with half of the memory on the server at /etc/default/elasticsearch.
- Also configure MAX_OPEN_FILES with 16K since it wont hit its limit in the long run.
Issue sending Email from the Ec2 instances
I configured the postfix recently on the ec2 instance and tried sending the mail with all the security group rules and NACL rules in place. However after i was initially able to telnet to the google email servers on port 25 soon i start getting logs with no connection error messages and ultimately i was not able to do telnet and even the mails were not going or received by the receiver.
This problem was only coming on the ec2 instances. This is because the Amazon throttles the traffic on the port 25 for all the Ec2 instance by default. But its possible to remove this throttling over the ec2 instance over the port 25.
For removing this limitation you need to create a DNS A record in the route53 to your instance used in the mail server such as postfix.
With the root account open the following link
https://aws-portal.amazon.com/gp/aws/html-forms-controller/contactus/ec2-email-limit-rdns-request
And provide your use case for sending the mail. Than you need to provide any reverse DNS record which might be required by the AWS to create as the reverse dns queries are used by the mail servers to verify the authenticity of the mail servers which are sending the mail and in turn lookout for these servers as mail is received to verify they are not sending mail so a proper resolution increases the chances of the mail being delivered to the inbox rather than spam.
Once the request is approved by the AWS Support you will receive a notification from the support team that the throttle limitations has been removed on your ec2 instance and you can send the mail to any recipient basis of your use cases.
This problem was only coming on the ec2 instances. This is because the Amazon throttles the traffic on the port 25 for all the Ec2 instance by default. But its possible to remove this throttling over the ec2 instance over the port 25.
For removing this limitation you need to create a DNS A record in the route53 to your instance used in the mail server such as postfix.
With the root account open the following link
https://aws-portal.amazon.com/gp/aws/html-forms-controller/contactus/ec2-email-limit-rdns-request
And provide your use case for sending the mail. Than you need to provide any reverse DNS record which might be required by the AWS to create as the reverse dns queries are used by the mail servers to verify the authenticity of the mail servers which are sending the mail and in turn lookout for these servers as mail is received to verify they are not sending mail so a proper resolution increases the chances of the mail being delivered to the inbox rather than spam.
Once the request is approved by the AWS Support you will receive a notification from the support team that the throttle limitations has been removed on your ec2 instance and you can send the mail to any recipient basis of your use cases.
SSH upgradation on the ubuntu for PCI Compliance
In case your security team raises a concern regarding the upgrading of the openssh server version on the ubuntu servers kindly refer to the openssh version based on the distribution before making any changes as this can effect the overall reachability to the server
Following are the latest openssh version based on the distribution
Following are the latest openssh version based on the distribution
OpenSSH 6.6 is the most recent version on Ubuntu 14.04.
OpenSSH 7.2 is the most recent version on Ubuntu 16.04.
OpenSSH 7.6 is the most recent version on Ubuntu 18.04.
Openssh 7.6 is supported on the Ubuntu 18.04 only and Ubuntu 14.04 is not compliant with it. Thats why its not upgraded during the patching activity.
Like all the other distribution ubuntu also backports the vulnerabilities so that the application compatibility doesn't break by changing versions between different distributions.
Dont make any changes to your server which are not compatible with your distribution version.
Go on providing the version of the ubuntu you are running.
This can be verified from the below links as well
Tuesday, October 2, 2018
Sunday, September 30, 2018
Wednesday, August 29, 2018
Managing Mysql Automated Failover on Ec2 instances with Orchestrator
Orchestrator is a free and opensource mysql high availability and replication management tool whose major functionalities includes MySQL/MariaDB MasterDB failover in seconds (10-20 secs) considering our requirements and managing replication topology (Changing Replication Architecture by drag-drop or via Orchestrator CLI) with ease.
Orchestrator has the following features:-
1. Discovery:- It actively crawls through the topologies and maps them and can read the basic replication status and configuration and provides slick visualisation of topologies including replication problems.
2. Refactoring:- Understands replication rules, knows about binlog file:position, GTID, Pseudo GTID, Binlog Servers.Refactoring replication topologies can be a matter of drag & drop a replica under another master.
3. Recovery:- It can detect master and intermediate master failures. It can be configured to perform automated recovery or allow user to choose manual recovery. Master failover supported with pre/post failure hooks.
Orchestrator has the following features:-
1. Discovery:- It actively crawls through the topologies and maps them and can read the basic replication status and configuration and provides slick visualisation of topologies including replication problems.
2. Refactoring:- Understands replication rules, knows about binlog file:position, GTID, Pseudo GTID, Binlog Servers.Refactoring replication topologies can be a matter of drag & drop a replica under another master.
3. Recovery:- It can detect master and intermediate master failures. It can be configured to perform automated recovery or allow user to choose manual recovery. Master failover supported with pre/post failure hooks.
Mysql Benchmarking with sysbench
Benchmarking helps to establish the performance parameters for a mysql database on different instance sizes in AWS Cloud
TOOL: sysbench
MySQL Version: 5.6.39-log MySQL Community Server (GPL)
EC2 Instance type: r4.xlarge (30 GB RAM, 4 CPU)
DB Size: 25 GB (10 tables)
TOOL: sysbench
MySQL Version: 5.6.39-log MySQL Community Server (GPL)
EC2 Instance type: r4.xlarge (30 GB RAM, 4 CPU)
DB Size: 25 GB (10 tables)
MySQL 5.6.39-log MySQL Community Server (GPL)
sysbench /usr/share/sysbench/oltp_read_write.lua --threads=32 --events=0 --time=120 --mysql-user=root --mysql-password=XXXXXXXXX --mysql-port=3306 --tables=10 --delete_inserts=10
--index_updates=10 --non_index_updates=0 --table-size=10000000 --db-ps-mode=disable --report-interval=5 --mysql-host=10.1.2.3 run
sysbench 1.0.15 (using bundled LuaJIT 2.1.0-beta2)
--index_updates=10 --non_index_updates=0 --table-size=10000000 --db-ps-mode=disable --report-interval=5 --mysql-host=10.1.2.3 run
sysbench 1.0.15 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 32
Report intermediate results every 5 second(s)
Initializing random number generator from current time
Number of threads: 32
Report intermediate results every 5 second(s)
Initializing random number generator from current time
Initializing worker threads...
Threads started!
[ 5s ] thds: 32 tps: 581.73 qps: 26855.28 (r/w/o: 8201.90/14784.53/3870.84) lat (ms,95%): 99.33 err/s: 0.00 reconn/s: 0.00
[ 10s ] thds: 32 tps: 586.70 qps: 26985.76 (r/w/o: 8222.39/14890.24/3873.13) lat (ms,95%): 97.55 err/s: 0.00 reconn/s: 0.00
.
[ 10s ] thds: 32 tps: 586.70 qps: 26985.76 (r/w/o: 8222.39/14890.24/3873.13) lat (ms,95%): 97.55 err/s: 0.00 reconn/s: 0.00
.
.
.
.
[ 120s ] thds: 32 tps: 570.20 qps: 26232.19 (r/w/o: 7987.66/14500.71/3745.83) lat (ms,95%): 77.19 err/s: 0.00 reconn/s: 0.00
[ 120s ] thds: 32 tps: 570.20 qps: 26232.19 (r/w/o: 7987.66/14500.71/3745.83) lat (ms,95%): 77.19 err/s: 0.00 reconn/s: 0.00
SQL statistics:
queries performed:
read: 969179
write: 1756892
other: 458342
total: 3184413
transactions: 69227 (576.70 per sec.)
queries: 3184414 (26528.16 per sec.)
ignored errors: 1 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
queries performed:
read: 969179
write: 1756892
other: 458342
total: 3184413
transactions: 69227 (576.70 per sec.)
queries: 3184414 (26528.16 per sec.)
ignored errors: 1 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 120.0371s
total number of events: 69226
total time: 120.0371s
total number of events: 69226
Latency (ms):
min: 10.15
avg: 55.48
max: 232.76
95th percentile: 82.96
sum: 3840451.69
min: 10.15
avg: 55.48
max: 232.76
95th percentile: 82.96
sum: 3840451.69
Threads fairness:
events (avg/stddev): 2163.3125/62.64
execution time (avg/stddev): 120.0141/0.01
events (avg/stddev): 2163.3125/62.64
execution time (avg/stddev): 120.0141/0.01
Upgrading AWS Instances to 5th Generation instances
Note: Latest AWS CLI version is required.
Once you've installed and configured the AWS CLI, and created an AMI, please follow the steps below:
1) SSH into your Ubuntu instance.
2) Upgrade the kernel on your instance by running the command:
sudo apt-get update && sudo apt-get install linux-image-generic
3) Stop the instance from the console or AWS CLI.
4) Using the AWS CLI, modify the instance attributes to enable ENA by running the command below:
aws ec2 modify-instance-attribute --instance-id --ena-support --region ap-southeast-1
5) Using the AWS CLI, modify the instance attributes to change to the desired instance type (for example: m5.large)
aws ec2 modify-instance-attribute --instance-id --instance-type m5.large --region ap-southeast-1
6) Start your instance from the console or the AWS CLI.
Once the instance boots, please confirm if the ENA module is in use on the network interface by running the command below:
ethtool -i eth0
1) SSH into your Ubuntu instance.
2) Upgrade the kernel on your instance by running the command:
sudo apt-get update && sudo apt-get install linux-image-generic
3) Stop the instance from the console or AWS CLI.
4) Using the AWS CLI, modify the instance attributes to enable ENA by running the command below:
aws ec2 modify-instance-attribute --instance-id
5) Using the AWS CLI, modify the instance attributes to change to the desired instance type (for example: m5.large)
aws ec2 modify-instance-attribute --instance-id
6) Start your instance from the console or the AWS CLI.
Once the instance boots, please confirm if the ENA module is in use on the network interface by running the command below:
ethtool -i eth0
New AMI (to launch new instances): v7 with ena support
Monday, August 27, 2018
Sunday, August 26, 2018
DynamoDB table getting throttled
Usually when a table is throttled while the consumed capacity is well below the provisioned capacity, it is an indicator of hot partition or a “burst” of read or write activity. Hot partition means one single partition is accessed more than other partitions and hence more capacity is consumed by that partition. Hot partition can be caused by unevenly distributed data across partitions due to hot partition key. A “burst” of read or write activity occurs when workloads rely on short periods of time with high usage, for example batch data upload.
Tagging EBS Volumes with Same tags as on EC2 instances in Autoscaling
Propagate the tags from a instance in an autoscaling group to the EBS volumes attached.
Although autoscaling group allows to apply tags to the instances this doesn't propagate to the instance volumes. So some scripting on user data section is needed during instance launch to properly tag the volumes of instances created by the autoscaling group.
You can use the below script to apply the tags to the EBS Volumes in an autoscaling group which should be created in the userdata field in the launch configuration of the autoscaling group. Also you need to attach a IAM role to the instance with the permissions of describe-instances,create-tags etc.
Although autoscaling group allows to apply tags to the instances this doesn't propagate to the instance volumes. So some scripting on user data section is needed during instance launch to properly tag the volumes of instances created by the autoscaling group.
You can use the below script to apply the tags to the EBS Volumes in an autoscaling group which should be created in the userdata field in the launch configuration of the autoscaling group. Also you need to attach a IAM role to the instance with the permissions of describe-instances,create-tags etc.
SSL certificate uploaded in AWS ACM but not available while create ELB/ALB
In case you have created an ACM SSL certificate however it is not available in the drop down list to associate with your load balancer.
The reason that you are unable to attach it to your ELB is because the certificate has a key length size of RSA-4096.
Although it is possible to import a SSL certificate of 4096 bits into ACM, currently the ELB supported Certificate types are RSA_1024 and RSA_2048. If you are using any other type of Certificate, it will unfortunately not be eligible for attachment to your ELB, which means that you won't be able to select it during the ELB creation process.
ACM supports 4096-bit RSA (RSA_4096) certificates but integrated services (such as ELBs) allow only algorithms and key sizes they support to be associated with their resources.
Note that ACM certificates (including certificates imported into ACM), are regional resources. Therefore, you must import your certificate into the same region that your ELB is in in order to associate it with the ELB.
The reason that you are unable to attach it to your ELB is because the certificate has a key length size of RSA-4096.
Although it is possible to import a SSL certificate of 4096 bits into ACM, currently the ELB supported Certificate types are RSA_1024 and RSA_2048. If you are using any other type of Certificate, it will unfortunately not be eligible for attachment to your ELB, which means that you won't be able to select it during the ELB creation process.
ACM supports 4096-bit RSA (RSA_4096) certificates but integrated services (such as ELBs) allow only algorithms and key sizes they support to be associated with their resources.
Note that ACM certificates (including certificates imported into ACM), are regional resources. Therefore, you must import your certificate into the same region that your ELB is in in order to associate it with the ELB.
Runbook to resolve some of the most common issues in Linux
Check the status of the particular FS by
df -ih
Check for the recently created files by entering the FS which is showing high inodes
find $1 -type f -print0 | xargs -0 stat --format '%Y :%y %n' | sort -nr | cut -d: -f2- | head
Check the directory which is having most of the files
find . -type d -print0 | xargs -0 -n1 count_files | sort -n
Creating a ssh config file so as not to pass the key or username in multiple servers
If you are running your servers in different VPC than based on the cidr range of the ip addresses and different username its difficult to remember all the keys and username while connecting to the servers.
Concepts for Rolling Deployment strategy for applications in production environment
Rolling deployment strategy follows wherein servers are taken out in a batch for deployment instead of deploying onto all servers at once. This helps in lowering the HTTP 5xx and other such issues when the traffic is high on the application and the deployment needs to be performed.
What Applications Qualifies for this Deployment:
- Applications running behind an Elastic load balancer.
- Application which have been moved to build and deploy model for NodeJS Applications (Wherein we build the deployment package once instead of doing on the fly compilation/installation)
Saturday, August 25, 2018
Switching Roles between Different AWS Accounts
If you are having the Infrastructure running in different AWS Accounts than you don't need to logout and login individually to each AWS Account or use the different browser. You can simply switch the roles between the different account
1. Login to your primary account this would be the entry level account through which you can switch to any of your other aws account.
2. Click on your username at the top of the screen and choose Switch Role > Then choose switch role again.
It will ask you for the following information
Account Number:- (Account number in which you want to switch from existing account)
Role:- (Role name which has been assigned to your user in IAM)
Display Name:- (Easy to recognise name e.g. Production-Appname)
3. Click on switch role and you should be in the other account without loging out from your current account.
4. When done editing revert back to your account.
5. You can add any number of accounts under the switch role and move between different accounts seamlessly.
1. Login to your primary account this would be the entry level account through which you can switch to any of your other aws account.
2. Click on your username at the top of the screen and choose Switch Role > Then choose switch role again.
It will ask you for the following information
Account Number:- (Account number in which you want to switch from existing account)
Role:- (Role name which has been assigned to your user in IAM)
Display Name:- (Easy to recognise name e.g. Production-Appname)
3. Click on switch role and you should be in the other account without loging out from your current account.
4. When done editing revert back to your account.
5. You can add any number of accounts under the switch role and move between different accounts seamlessly.
Kubernetes Terminology
Kubernetes Master:- The master nodes in the kubernetes is a node which controls all the other nodes in the cluster. There can be several of those master nodes in a cluster if its said to be highly available or there can only be 1 if you got a single node cluster than that node will always going to be a master node.
Kube-Apiserver:- Is the main part of the cluster which answer all the apicalls. This uses the key value store for storing the configuration of other persistent storage such as ETCD.
ETCD:- Etcd is open source distributed key value store that provides the shared onfiguration and service discovery for the containers linux clusters. etcd runs on each machine in a cluster and gracefully handles the leader election during the network partitions and loss of the current leader. It is responsible for storing and replicating all kubernetes cluster state.
Service Discovery:- It is the automatic detection of the devices and services offerentby the devices on a computer network which uses service discovery protocol (SDP) which is network protocol that helps accompllish service discovery that aims to reduce the configuration effort from users.
Kube-Scheduler:- IT is reponsible for pods and there requisite containers which are going to come up on the cluster.Kube-Scheduler needs to take into account individual and collective resource requirements, hardware/software/policy constraints,data locality, interworkload interferene and so on. Workload specific requirements will be exposed through the API as necessary.
Cloud-Controller-Manager:- It is a daemon that embeds cloud-specific control loops. Since cloud provider develop and release at a different pace compared to the kubernetes project, abstracting the provider-specific code to the cloud-controller-manager binary allows cloud vendors to evolve independently from the core kubernetes code. It is responsible for persistent storage, routes for networking.
Control loop:- In application of automation, a control loop is a non terminating loop that regulates the state of the system.
Kube-Controller-Manager:- It is a daemon which embeds the control loop which ships with the kubernetes. It is a control loop that watches the shared state of the cluster through the apiserver and makes changes attempting to move the current state towards the desired state. For e.g. Kubernetes uses replication controller, endpoint controller, namespace controller and serviceaccounts controller. Kube-Controller manager can use the Cloud-Controller manager to expose them to the cloud.
Node:- It was previously refered to as the minions. Node is worker machine in kubernetes and it can be VM or physical machine depending on the cluster. Each node contains services necessary to run pods and is managed by the master components. The service on a node include the container runtime, kubelet and kube-proxy.
Kubelet:- Kubelet is the primary "node agent" which runs on each node and works in terms of PodSpec. A PodSpec is a YAML or Json object that describes a pod. The Kubelet takes a set of PodSpecs that are provided through various mechanisms primarily through the KubeApiserver and ensures the containers running in those PodSpecs are running and healthy.
Kube-proxy:- It runs on each node in the cluster. This reflects services as defined in the Kubernetes API on each node and can do simple TCP and UDP stream forwarding/RoundRobin across a set of the backends. Service cluster IPs and ports are currently found through Docker-links-compatible-environment variables specifying the ports opened by the service proxy. There is an optional addon that provides cluster DNS for these cluster IPs. The user must create a service with apiserver API to configure the proxy.
Kube-Apiserver:- Is the main part of the cluster which answer all the apicalls. This uses the key value store for storing the configuration of other persistent storage such as ETCD.
ETCD:- Etcd is open source distributed key value store that provides the shared onfiguration and service discovery for the containers linux clusters. etcd runs on each machine in a cluster and gracefully handles the leader election during the network partitions and loss of the current leader. It is responsible for storing and replicating all kubernetes cluster state.
Service Discovery:- It is the automatic detection of the devices and services offerentby the devices on a computer network which uses service discovery protocol (SDP) which is network protocol that helps accompllish service discovery that aims to reduce the configuration effort from users.
Kube-Scheduler:- IT is reponsible for pods and there requisite containers which are going to come up on the cluster.Kube-Scheduler needs to take into account individual and collective resource requirements, hardware/software/policy constraints,data locality, interworkload interferene and so on. Workload specific requirements will be exposed through the API as necessary.
Cloud-Controller-Manager:- It is a daemon that embeds cloud-specific control loops. Since cloud provider develop and release at a different pace compared to the kubernetes project, abstracting the provider-specific code to the cloud-controller-manager binary allows cloud vendors to evolve independently from the core kubernetes code. It is responsible for persistent storage, routes for networking.
Control loop:- In application of automation, a control loop is a non terminating loop that regulates the state of the system.
Kube-Controller-Manager:- It is a daemon which embeds the control loop which ships with the kubernetes. It is a control loop that watches the shared state of the cluster through the apiserver and makes changes attempting to move the current state towards the desired state. For e.g. Kubernetes uses replication controller, endpoint controller, namespace controller and serviceaccounts controller. Kube-Controller manager can use the Cloud-Controller manager to expose them to the cloud.
Node:- It was previously refered to as the minions. Node is worker machine in kubernetes and it can be VM or physical machine depending on the cluster. Each node contains services necessary to run pods and is managed by the master components. The service on a node include the container runtime, kubelet and kube-proxy.
Kubelet:- Kubelet is the primary "node agent" which runs on each node and works in terms of PodSpec. A PodSpec is a YAML or Json object that describes a pod. The Kubelet takes a set of PodSpecs that are provided through various mechanisms primarily through the KubeApiserver and ensures the containers running in those PodSpecs are running and healthy.
Kube-proxy:- It runs on each node in the cluster. This reflects services as defined in the Kubernetes API on each node and can do simple TCP and UDP stream forwarding/RoundRobin across a set of the backends. Service cluster IPs and ports are currently found through Docker-links-compatible-environment variables specifying the ports opened by the service proxy. There is an optional addon that provides cluster DNS for these cluster IPs. The user must create a service with apiserver API to configure the proxy.
Important points to consider while create zookeepeer and kafka cluster
The kafka queue is a highly scalable and extreme fast queuing service which can really come in handy when you have to handle large amount of messages and have to build and services to work in async mode with an option to handle the fault in the services but not loosing the data at the same time you need the system to be scalable which can meet the ever growing demand of messages which would be pushed to this cluster.
Following are some of the important points to consider while creating the highly available kafka zookeeper cluster:-
1. If you want to scale your kafka nodes you should consider keeping the zookeeper on the separate nodes. This is particularly useful for environment where kafka messages throughput is extremely large and more number of brokers would be required after certain period of time to deal with the fault tolerance while maintaining the system to be scalable.
Kafka in itself is very scalable solution and in case you are not getting the data in TBs you can consider to keep the kafka and zookeeper on same nodes which will help you in the cost saving of the instances if you are running it in the cloud. So the best approach is the end use of the kafka and how much messages will it be handling over a period of time and the scalability required overall.
2. Zookeeper nodes saves the overall state of kafka cluster so your zookeeper cluster can be smaller in resources of infrastructure as compared to the kafka cluster. You should use the bigger instance sizes and more disk space in the kafka cluster than the zookeeper cluster.
Following are some of the important points to consider while creating the highly available kafka zookeeper cluster:-
1. If you want to scale your kafka nodes you should consider keeping the zookeeper on the separate nodes. This is particularly useful for environment where kafka messages throughput is extremely large and more number of brokers would be required after certain period of time to deal with the fault tolerance while maintaining the system to be scalable.
Kafka in itself is very scalable solution and in case you are not getting the data in TBs you can consider to keep the kafka and zookeeper on same nodes which will help you in the cost saving of the instances if you are running it in the cloud. So the best approach is the end use of the kafka and how much messages will it be handling over a period of time and the scalability required overall.
2. Zookeeper nodes saves the overall state of kafka cluster so your zookeeper cluster can be smaller in resources of infrastructure as compared to the kafka cluster. You should use the bigger instance sizes and more disk space in the kafka cluster than the zookeeper cluster.
Sunday, August 19, 2018
Thursday, July 19, 2018
Setting Security team email for security related issues in AWS Account
Follow the steps below to fill the security team email this can come handy to respond to the security related issues in the AWS Account
1. Sign in to the AWS Management Console and open the Billing and Cost Management console at https://console.aws.amazon.com/billing/home#/.
2. On the navigation bar, choose your account name, and then choose My Account.
3. Scroll down to the Alternate Contacts section, and then choose Edit.
4. For the fields (in this case, Security Contact) that you want to change, type your updated information, and then choose Update.
These alternate contacts, which include the Security Contact, enable AWS to contact another person about issues with your account, even if you're not attending to this account regularly.
Regards
Ankit Mittal
1. Sign in to the AWS Management Console and open the Billing and Cost Management console at https://console.aws.amazon.com/billing/home#/.
2. On the navigation bar, choose your account name, and then choose My Account.
3. Scroll down to the Alternate Contacts section, and then choose Edit.
4. For the fields (in this case, Security Contact) that you want to change, type your updated information, and then choose Update.
These alternate contacts, which include the Security Contact, enable AWS to contact another person about issues with your account, even if you're not attending to this account regularly.
Regards
Ankit Mittal
Sunday, July 8, 2018
Configuring the dynamic inventory for Ansible
If you are running large number of servers in aws or using the autoscaling than its not possible to maintain the hosts entry in the hosts file of the ansible.
Instead you can use the dynamic inventory which is a python script. ec2.py available on the ansible and free to use. You can configure the python script as follows and target the ec2 instances to make the configuration changes via ansible even on the autoscaling instances using the tags.
1. Download the Ansible dynamic inventory script
wget https://raw.github.com/ansible/ansible/devel/contrib/inventory/ec2.py
2. Make the script executable
chmod +x ec2.py
3. Attach the role to the ec2 instance from which you are going to run the ansible and attach appropriate policy to the role with permissions which would be required by ansible for the configuration management.
4. If you are using the private instances than chances are you might receive the empty list when you run the ./ec2.py --list command to test the dynamic inventory. To resolve this issue open the ec2.py and make the following changes
'vpc_destination_variable': 'private_ip_address'
5. Run the ec2.py script again and it will list all the instances based on the tags.
./ec2.py --list
6. You can set the tags and call through ansible and ansible will push the configuration based on the tags.
Instead you can use the dynamic inventory which is a python script. ec2.py available on the ansible and free to use. You can configure the python script as follows and target the ec2 instances to make the configuration changes via ansible even on the autoscaling instances using the tags.
1. Download the Ansible dynamic inventory script
wget https://raw.github.com/ansible/ansible/devel/contrib/inventory/ec2.py
2. Make the script executable
chmod +x ec2.py
3. Attach the role to the ec2 instance from which you are going to run the ansible and attach appropriate policy to the role with permissions which would be required by ansible for the configuration management.
4. If you are using the private instances than chances are you might receive the empty list when you run the ./ec2.py --list command to test the dynamic inventory. To resolve this issue open the ec2.py and make the following changes
'vpc_destination_variable': 'private_ip_address'
5. Run the ec2.py script again and it will list all the instances based on the tags.
./ec2.py --list
6. You can set the tags and call through ansible and ansible will push the configuration based on the tags.
Friday, June 1, 2018
Starting and Stopping Ec2 instances Automatically during Night for Non-prod Environment for Saving on the AWS Billing
The following script can be used to start and stop the Ec2 instances during the non-productive ours for the lower environment such as Development, Sit, stage etc. Depending on the number of instances that are stopped you can save on your AWS Billing.
You can align the script to run during the defined ours using Cron job. The advantage of the script is that everytime you need to add an server to automatically start and stop you just need to enter in the Tag with specified values in our case its ADMIN_EC2_STARTSTOP which can have the values of stop or start and it would automatically add the instance to this setup. You don't have to change the script everytime a new server is being created.
The script uses an additional tag of Environment to identify the Environment to start and stopped as it can be possible that you want to stop the Stage and Dev environment at different times and different days depending upon your requirement. So you dont have to change the script same script can achieve this task.
Lastly script uses the key as same environment has same key usually to identify the name of the instance. though its possible to tweak this into the script to identify the name of the instance depending on the instance id.
The Example implementation of this code is below
#Login to the server for which you have the aws cli installed and through which you want to run this script and set the crontab for this user as below
#crontab -e
# Development Environment
# Working Window : 8:00 am to 11:55 pm [Monday ~ Saturday]
55 23 * * * /opt/script_automation/ec2_instance_run_scheduler.sh stop Development
0 8 * * 1,2,3,4,5,6 /opt/script_automation/ec2_instance_run_scheduler.sh start Development
The working window defines the time during which our Development Environment will be available to the users to work.
Using this script you can automatically stop and start your environment and save on the AWS Billing.
You can align the script to run during the defined ours using Cron job. The advantage of the script is that everytime you need to add an server to automatically start and stop you just need to enter in the Tag with specified values in our case its ADMIN_EC2_STARTSTOP which can have the values of stop or start and it would automatically add the instance to this setup. You don't have to change the script everytime a new server is being created.
The script uses an additional tag of Environment to identify the Environment to start and stopped as it can be possible that you want to stop the Stage and Dev environment at different times and different days depending upon your requirement. So you dont have to change the script same script can achieve this task.
Lastly script uses the key as same environment has same key usually to identify the name of the instance. though its possible to tweak this into the script to identify the name of the instance depending on the instance id.
#!/bin/bash
#
#
# This script can be used for performing start/stop of ec2 instances. We can schedule the script using crontab for performing schedule based start/stop operations
#
# We can pass filters (only Key type) in order to filter out ec2 instance before performing start/stop operations
#
# Requirements:
# * The script works with ec2 instances which have the following Tag (Key=Value)
# ADMIN_EC2_STARTSTOP=[Yes = Auto Start/Stop Enabled | No = Auto Start/Stop Disabled]
#
#
#
OUTPUT=text;
FILTER='"Name=tag:ADMIN_EC2_STARTSTOP,Values=Yes"';
# We need to provide the name of the Environment and
# action to perform
#
usage(){
echo -e "Usage:\n";
echo -e "$0 <start|stop> [Environment Name] \n";
echo "Examples:";
echo 'Starting All Instances in Stage Environment"';
echo " # $0"' Start Stage';
exit 0;
}
# Two inputs required to execute the script
if [ $# -ne 2 ];
then
usage;
fi;
# Check if valid action is provided for the script
ACTION=$1;
if [[ $ACTION != "start" && $ACTION != "stop" ]];# && $1 != "stop" ];
then
usage;
fi;
ENVIRONMENT=$2;
echo "Environment : $ENVIRONMENT"
# Assign AWS Instance Current State according to the action required to be performed.
# AWS Instance State Code
# Stopped State : 80
# Running State : 16
if [ $ACTION == "start" ];
then
INSTANCE_CURRENT_STATE=80;
echo "Action : Starting Instances";
fi;
if [ $ACTION == "stop" ];
then
INSTANCE_CURRENT_STATE=16;
echo -e "Action : Stopping Instances\n";
fi;
echo -e "Sno.\tInstance_ID\tPrivate_DNS_Name\t\t\t\tInstance_Name";
count=1;
for INSTANCE_ID in `aws ec2 describe-instances --output text --query 'Reservations[].Instances[].InstanceId' --filters "Name=tag:ADMIN_EC2_STARTSTOP,Values=Yes" "Name=instance-state-code,Values=${INSTANCE_CURRENT_STATE}" "Name=tag:Environment,Values=${ENVIRONMENT}"`;
do
## Get Name
INST_NAME=$(aws ec2 describe-instances --query 'Reservations[].Instances[].[Tags[?Key==`Name`].Value]' --filters "Name=instance-id,Values=${INSTANCE_ID}" --output text);
## Get Private Hostname
INST_PRIVATE_DNSNAME=$(aws ec2 describe-instances --query 'Reservations[*].Instances[*].[PrivateDnsName]' --filters "Name=instance-id,Values=${INSTANCE_ID}" --output=text);
## Execute Operations
echo -e "$count\t$INSTANCE_ID\t$INST_PRIVATE_DNSNAME\t$INST_NAME";
count=$((count + 1));
if [ $ACTION == "start" ];
then
aws ec2 start-instances --instance-ids $INSTANCE_ID &>/dev/null
fi;
if [ $ACTION == "stop" ];
then
aws ec2 stop-instances --instance-ids $INSTANCE_ID &>/dev/null
fi;
done;
The Example implementation of this code is below
#Login to the server for which you have the aws cli installed and through which you want to run this script and set the crontab for this user as below
#crontab -e
# Development Environment
# Working Window : 8:00 am to 11:55 pm [Monday ~ Saturday]
55 23 * * * /opt/script_automation/ec2_instance_run_scheduler.sh stop Development
0 8 * * 1,2,3,4,5,6 /opt/script_automation/ec2_instance_run_scheduler.sh start Development
The working window defines the time during which our Development Environment will be available to the users to work.
Using this script you can automatically stop and start your environment and save on the AWS Billing.
Wednesday, March 21, 2018
Using aws config to monitor Stacks with Screenshots
Aws config can be used to monitor the instances, security group and other resources within you AWS Account. This is specially useful to monitor the compliance of the instances and to raisae alarm if someone creates an instance without the proper procedure like missing tags, changes in the security group, non compliant instance type etc.
Aws config will mark them as non-compliant under the config dashboard and can send a notification using the SNS service.It can easily be deployed using the cloudformation and helps in managing the resource effectively. This is specially recommended in case you have many users in your organization with the dashboard access who have privilege to create the instances.
Follow the procedure descripbed below to configure the aws config in your environment for the ec2 instances where you can define the instances which are compliant in your aws account any instance apart from them would be marked as non-compliant and you configure an alert for the same.
Start by selecting the Config service from the aws dashboard

If you haven't configured the Aws config start by clicking "Get Started"

Aws config will mark them as non-compliant under the config dashboard and can send a notification using the SNS service.It can easily be deployed using the cloudformation and helps in managing the resource effectively. This is specially recommended in case you have many users in your organization with the dashboard access who have privilege to create the instances.
Follow the procedure descripbed below to configure the aws config in your environment for the ec2 instances where you can define the instances which are compliant in your aws account any instance apart from them would be marked as non-compliant and you configure an alert for the same.
Start by selecting the Config service from the aws dashboard

If you haven't configured the Aws config start by clicking "Get Started"

Thursday, March 8, 2018
Installing php
3. PHP Installation
Version: 5.3.17
export CFLAGS=-m64
export LDFLAGS=-m64
yum install libjpeg-devel
yum install libpng-devel
yum install libtiff-devel
yum install libtool-ltdl-devel
yum install freetype-devel
Install libmcrypt-devel
Install libmcrypt
tar -zxvf mm-1.4.2.tar.gz
make
make test
make install
tar -xvzf php-5.3.17.tar.gz
cd php-5.3.17
'./configure' '--prefix=/usr' '--with-libdir=lib64' '--libdir=/usr/lib64/' '--with-config-file-path=/etc' '--with-config-file-scan-dir=/etc/php.d' '--with-apxs2=/opt/www/apache/2.2.23/bin/apxs' '--with-libxml-dir=/usr' '--with-curl=/usr' '--with-mysql' '--with-zlib' '--with-zlib-dir=/usr' '--enable-sigchild' '--libexecdir=/usr/libexec' '--with-libdir=lib64' '--enable-sigchild' '--with-bz2' '--with-curl' '--with-exec-dir=/usr/bin' '--with-openssl' '--with-libexpat-dir=/usr' '--enable-exif' '--enable-ftp' '--enable-magic-quotes' '--enable-sockets' '--enable-sysvsem' '--enable-sysvshm' '--enable-sysvmsg' '--enable-wddx' '--with-kerberos' '--enable-ucd-snmp-hack' '--enable-shmop' '--enable-calendar' '--with-xmlrpc' '--with-pdo-mysql=/usr' '--enable-pcntl' '--disable-debug' '--enable-inline-optimization' '--enable-mbstring' '--enable-safe-mode' '--enable-wddx=shared' '--with-regex=system' '--enable-xml' '--enable-soap' '--with-mcrypt=/usr' '--enable-inline-optimization' '--enable-mbregex' '--enable-shmop' '--with-xsl' '--with-gd' '--with-png-dir=/usr' '--with-jpeg-dir=/usr' '--enable-gd-native-ttf' '--with-iconv' '--enable-sockets' '--enable-sysvsem' '--enable-sysvshm' '--enable-sysvmsg' '--enable-trans-sid' '--with-kerberos' '--enable-ucd-snmp-hack' '--enable-shmop' '--enable-calendar' '--enable-dbx' '--enable-dio' '--with-xmlrpc' '--enable-soap' '--enable-pdo' '--with-openssl' '--with-xsl' '--with-mm=shared' '--enable-mbstring' '--with-mcrypt=/usr' '--enable-zip' '--with-xml2' '--with-freetype-dir=/usr'
make
make install
remove dbase.ini & ldap.ini from /etc/php.d
change extension_dir in /etc/php.ini to /usr/lib64/extensions/no-debug-non-zts-20090626/
Tuesday, March 6, 2018
Upgrading Kernel Version on Aws Ec2 instance
There are multiple requirements for upgrading the Kernel version on the Ec2 instance on the AWS instances. You will definitely want to upgrade for the bug fixes and the stability which comes with the updated version.
In our case we have to install the Antivirus required for the audit purpose but the issue arise when we were using the older version of the Kernel which was not supported by the Antivirus. This was particularly essential since antivirus provides you with active defense against unknown threats which are not included in the free antivirus. So we were required to update the kernel version.
We were running the 3.13.0-105-lowlatency version of the kernel however the following version was supported by the Antivirus. We were required to upgrade the kernel to 3.13.0-142-generic for the antivirus to work.
Upgrading the kernel version on the Aws ec2 instances can be little tricky because if you don't do it properly it would certainly cause the startup failures. We already faced issues with one of our instance when we initially tried to upgrade the kernel version through apt directly after the restart the status checks for the instance reachability got failed and this in-turned added the complexity during the upgrade. I am going to discuss in a separate post , how you can recover an instance in case you have corrupted the kernel upgrade and Ec2 instance fails to start due to Ec2 instance health check failures.
Its good to take the snapshot of the volumes separately for such scenarios in case your instance fails to start you can create new volume out of the snapshot, replace the old volumes with new and you should be able to start the instance without any issues. This is particularly the best saviour you have in case something goes wrong during the kernel upgrade.
Once the snapshot is completed you just need to install the package bikeshed. ∫Bikeshed comes with additional binaries which are not shipped with the Linux distros by default.
In our case we have to install the Antivirus required for the audit purpose but the issue arise when we were using the older version of the Kernel which was not supported by the Antivirus. This was particularly essential since antivirus provides you with active defense against unknown threats which are not included in the free antivirus. So we were required to update the kernel version.
We were running the 3.13.0-105-lowlatency version of the kernel however the following version was supported by the Antivirus. We were required to upgrade the kernel to 3.13.0-142-generic for the antivirus to work.
Upgrading the kernel version on the Aws ec2 instances can be little tricky because if you don't do it properly it would certainly cause the startup failures. We already faced issues with one of our instance when we initially tried to upgrade the kernel version through apt directly after the restart the status checks for the instance reachability got failed and this in-turned added the complexity during the upgrade. I am going to discuss in a separate post , how you can recover an instance in case you have corrupted the kernel upgrade and Ec2 instance fails to start due to Ec2 instance health check failures.
Its good to take the snapshot of the volumes separately for such scenarios in case your instance fails to start you can create new volume out of the snapshot, replace the old volumes with new and you should be able to start the instance without any issues. This is particularly the best saviour you have in case something goes wrong during the kernel upgrade.
Once the snapshot is completed you just need to install the package bikeshed. ∫Bikeshed comes with additional binaries which are not shipped with the Linux distros by default.
# apt-get install bikeshed Friday, March 2, 2018
Machine Learning Use Cases in the Financial Services
With the rapid changing digital age and our more dependence on the digital services in every domain from banking, payments, medical, ecommerce, investments etc needs a technology delivery model that's suited to how the world and consumer needs are changing so as to allow companies to develop new products and capabilities that kind of fits with the digital age.
We are considering the Capital One's use case for the Machine learning
There were 3 main fields for the Capital one to improve there banking relationship - Fraud Detection, Credit Risk, Cybersecurity. Improving these areas involves distinguishing patterns, something the neural networks underlying machine learning accomplish far better than traditional , non-AI software. The goals were to Approve as many transactions as possible by identifying fraud only when it's very likely to happen; make better decisions making around credit risk, track constantly evolving threats. Applying machine learning to these areas is a big oppurtunity.
One recent innovation for the same was a tool called SECOND LOOK , which uses machine learning to alert customers about unusual spending patterns, such as double charges, a repeating charge that is higher than the previous month , or a tip that's higher than the norm. According to the company , Second look saved customers millions of dollars in unwanted charges.
We are considering the Capital One's use case for the Machine learning
There were 3 main fields for the Capital one to improve there banking relationship - Fraud Detection, Credit Risk, Cybersecurity. Improving these areas involves distinguishing patterns, something the neural networks underlying machine learning accomplish far better than traditional , non-AI software. The goals were to Approve as many transactions as possible by identifying fraud only when it's very likely to happen; make better decisions making around credit risk, track constantly evolving threats. Applying machine learning to these areas is a big oppurtunity.
One recent innovation for the same was a tool called SECOND LOOK , which uses machine learning to alert customers about unusual spending patterns, such as double charges, a repeating charge that is higher than the previous month , or a tip that's higher than the norm. According to the company , Second look saved customers millions of dollars in unwanted charges.
Thursday, March 1, 2018
Using the Comments in the Python
You can use the # for single line comments.
# This is comment # this is also comment
There is no concept of multi line comments in the python so you would need to enter the # infront of every line you want to comment in multiline case.
# This is comment # this is also comment
There is no concept of multi line comments in the python so you would need to enter the # infront of every line you want to comment in multiline case.
Creating and Running python scripts
You can simply start by creating a file which ends in the extension .py like
vim hello.py
Than just start by entering the print command
print ("Hello, World!")
Than you can execute this file with the python as follows
python hello.py
If you want to make this executable use the # in the linux as follows
#!/bin/python
chmod +x hello.py
afterwards you can simply execute it like
./hello.py
Now always keep the executables in the bin directory
mkdir bin
mv hello.py bin/hello
This way you can simply make it a command which can directly be executed in the linux terminal and this is how most of the commands actually work in the Linux
You just need to modify the source to match yours , it can be done as follows
source PATH=$PATH:$HOME/bin/
vim hello.py
Than just start by entering the print command
print ("Hello, World!")
Than you can execute this file with the python as follows
python hello.py
If you want to make this executable use the # in the linux as follows
#!/bin/python
chmod +x hello.py
afterwards you can simply execute it like
./hello.py
Now always keep the executables in the bin directory
mkdir bin
mv hello.py bin/hello
This way you can simply make it a command which can directly be executed in the linux terminal and this is how most of the commands actually work in the Linux
You just need to modify the source to match yours , it can be done as follows
source PATH=$PATH:$HOME/bin/
REPL in the python
REPL in python Read Evaluate print Loop . It helps you to work with the python the easy way when you start learning the python initially. You can simply login to the python by just writing the python on the terminal window. And once you evaluated than you exit out using the exit() function remember it neads () otherwise just writing the exit wouldn't allow you to log out.
History of the Python
1. Created by Guido van Rossum
2. First apperance in 1991
3. Used and supported by the tech giants like google and youtube.
4. Supported two major version for nearly a decade (python2 and python3)
5. Object oriented Scripting Language
6. Dynamic and Strong type system
7. Functional Concepts (map,reduce,filter,etc)
8. Whitespace delimited with pseudo-code like syntax
9. Used across a variety of descipilines, including:
a.) Academia
b.) Data Science
c.) Devops
d.) Web Development
10. Runs on all major operating systems.
11. Consistently high on the Tiobe index
Wednesday, February 7, 2018
[Devops Job Openings] OPtum(UHG) opening for Linux Admin
Greetings from Naukri.com!!
We all know in this competitive scenario everyone is growing so fast. And in order to cope up with ever changing environment, it is imperative to tap the current opportunity before its being taken over by someone else. Here is an opportunity for you; your profile has been shortlisted from Naukri.com job portals.
Devops Manager || 4-10 Yrs || Noida
| Job Synopsis | ||||||||||||||
| ||||||||||||||
| Job Description | ||||||||||||||
| ||||||||||||||
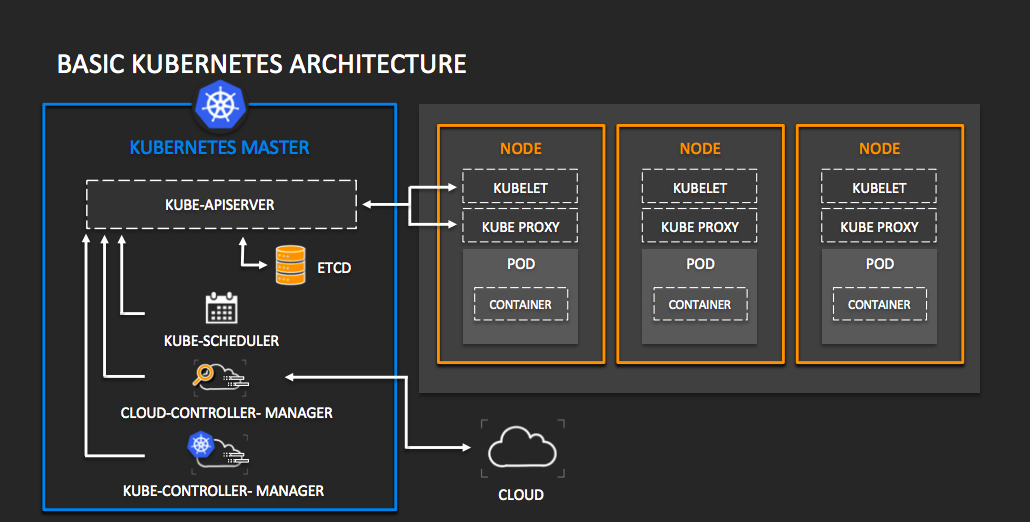
Subscribe to:
Posts (Atom)
